Spring 循环依赖
一、Spring 循环依赖完整流程图

二、三级缓存
Spring 在启动过程中,使用到了三个map,称为三级缓存
/** 单例对象的缓存[一级缓存] */
private final Map<String, Object> singletonObjects = new ConcurrentHashMap<>(256);
/** 单例对象工厂的缓存[三级缓存] */
private final Map<String, ObjectFactory<?>> singletonFactories = new HashMap<>(16);
/** 提前曝光的单例对象的缓存[二级缓存] */
private final Map<String, Object> earlySingletonObjects = new HashMap<>(16);流程描述
Spring启动过程大致如下:
- 0.容器初始化的一些环境准备
- 1.创建BeanFactory对象
- 2.
加载配置文件并解析配置文件封装为beanDefination - 3.给beanFactory设置一些属性, 比如
beanDefination、各个后置处理器等 - 4.创建
非延迟加载的单例bean
一级缓存
在以上第4步中,所有单例的 bean 创建完成后会存放在一个Map singletonObjects中,其 beanName为key,单例bean为value。
这也称之为 一级缓存,
上述第4步单例bean的创建过程大致如下:
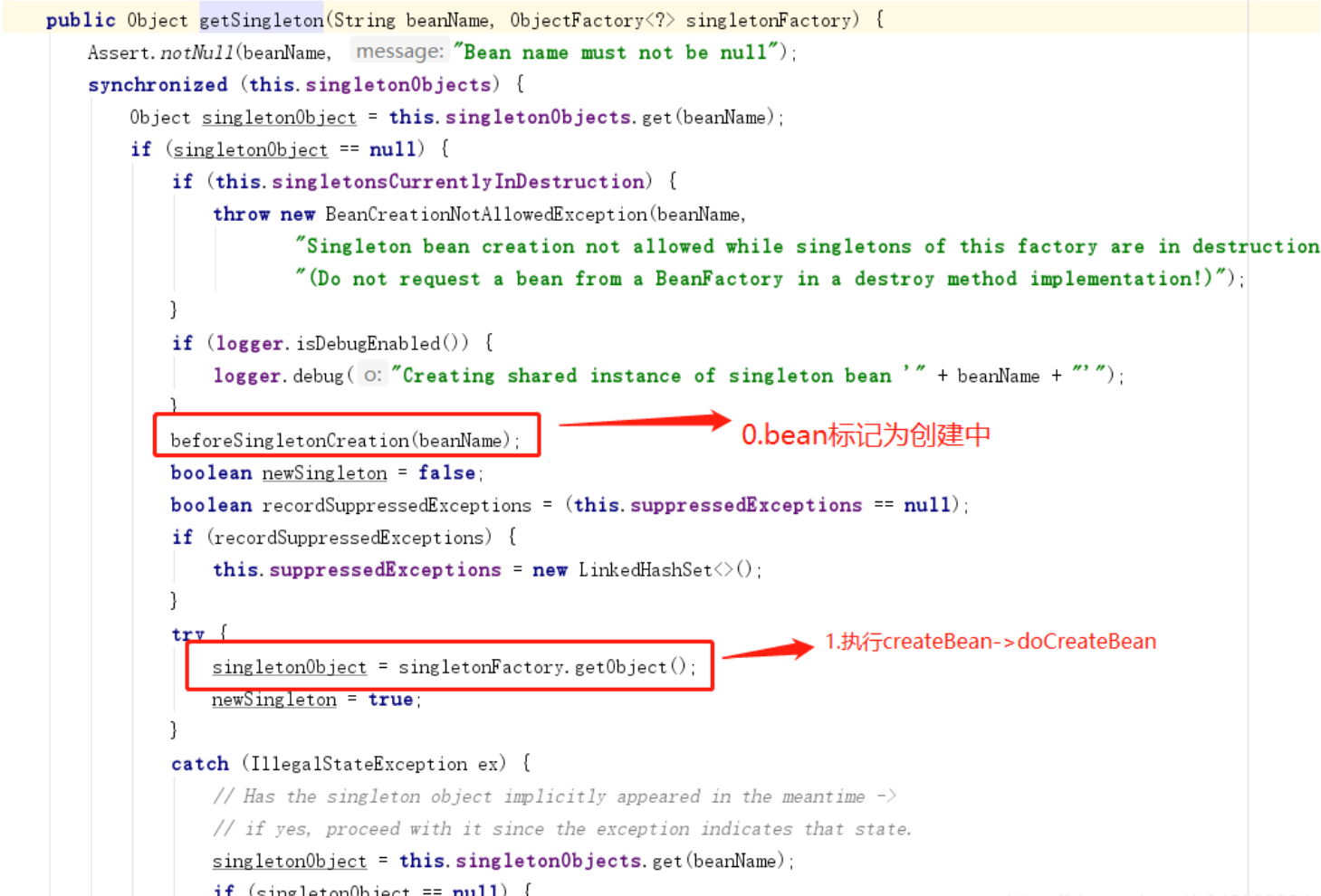
- 0.标记bean为创建中
- 1.new出bean对象
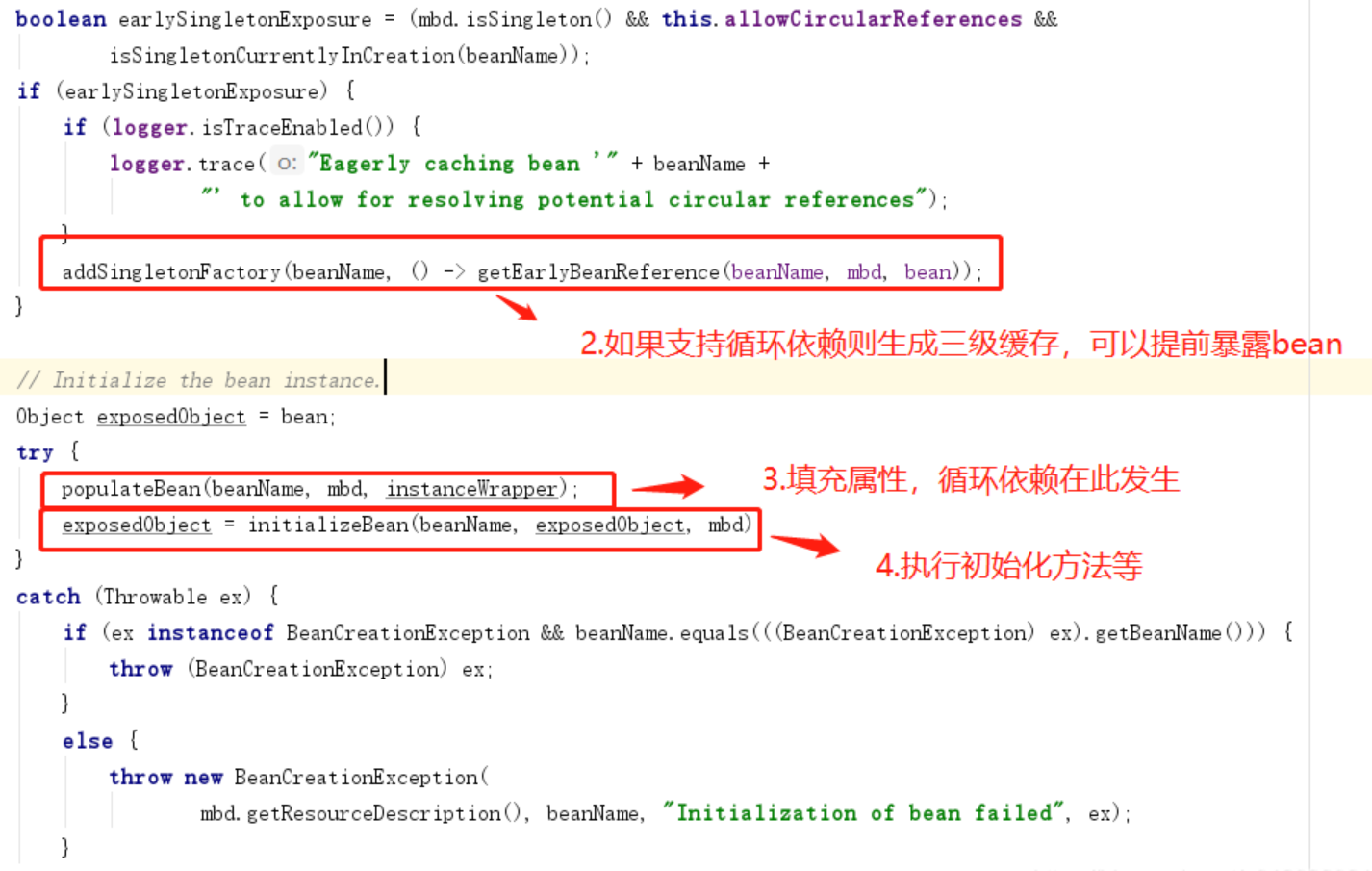
- 2.如果支持循环依赖则生成三级缓存,可以提前暴露bean
- 3.填充bean属性,如果存在循环依赖,解决之
- 4.初始化bean,处理Aware接口并执行各类bean后处理器,执行初始化方法,如果需要生成aop代理对象
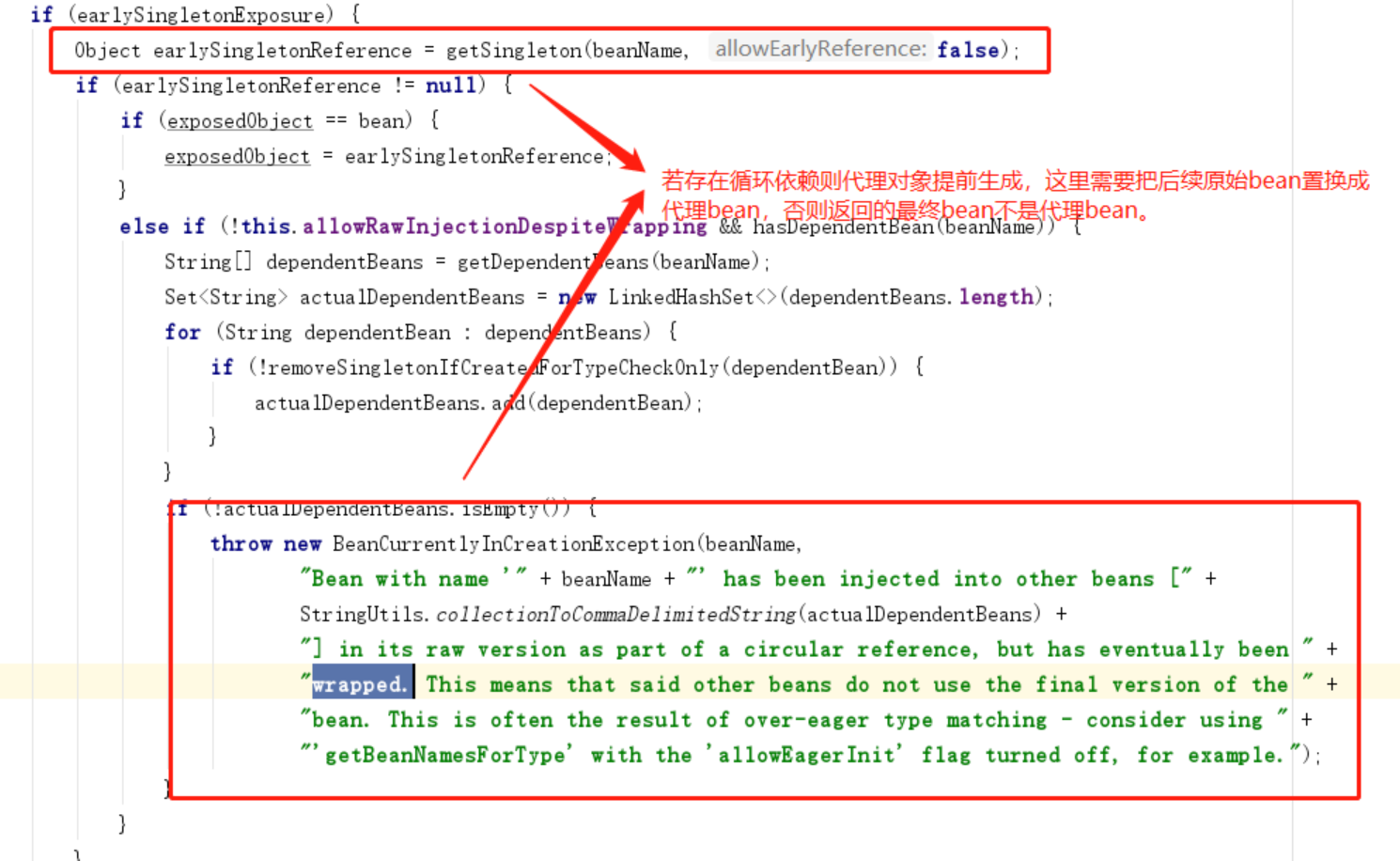
- 5.这里有点问题,这一步是如果之前解决了aop循环依赖,则缓存中放置了提前生成的代理对象,然后使用原始bean继续执行初始化,所以需要再返回最终bean前,把原始bean置换为代理对象返回。
- 6.此时返回的 bean 已经可以被使用,将 bean 放入容器中(
一级缓存 singletonObjects),移除创建中标记及二三级缓存(后面再具体分析)
循环依赖及三级缓存
根据以上步骤可以看出bean初始化是一个相当复杂的过程,假如初始化A bean时,发现A bean依赖B bean, 即A初始化执行到了第2步,此时B还没有初始化,则需要暂停A,先去初始化B,那么此时new出来的A对象放哪里,直接放在容器Map里显然不合适,半残品怎么能用,所以需要提供一个可以标记创建中bean(A)的Map,可以提前暴露正在创建的bean供其他bean依赖,如果在初始化A所依赖的bean B时,发现B也需要注入一个A的依赖,则B可以从创建中的beanMap中直接获取A对象(创建中)注入A,然后完成B的初始化,返回给正在注入属性的A,最终A也完成初始化,皆大欢喜。
如果配置不允许循环依赖,则上述缓存就用不到了,A 依赖B,就是创建B,B依赖C就去创建C,创建完了逐级返回就行,所以,一级缓存之后的其他缓存(二三级缓存)就是为了解决循环依赖!而配置支持循环依赖后,就一定要解决循环依赖吗?肯定不是!循环依赖在实际应用中也有,但不会太多,简单的应用场景是: controller注入service,service注入mapper,只有复杂的业务,可能service互相引用,有可能出现循环依赖,所以为了出现循环依赖才去解决,不出现就不解决,虽然支持循环依赖,但是只有在出现循环依赖时才真正暴露早期对象,否则只暴露个获取bean的方法,并没有真正暴露bean,因为这个方法不会被执行到,这块的实现就是三级缓存(singletonFactories),只缓存了一个单例bean工厂

这个bean工厂不仅可以暴露早期bean 还可以 暴露代理bean,如果存在aop代理,则依赖的应该是代理对象,而不是原始的bean。而暴露原始bean是在单例bean初始化的第2步,填充属性第3步,生成代理对象第4步,这就矛盾了,A依赖到B并去解决B依赖时,要去初始化B,然后B又回来依赖A,而此时A还没有执行代理的过程,所以,需要在填充属性前就生成A的代理并暴露出去,第2步时机就刚刚好。
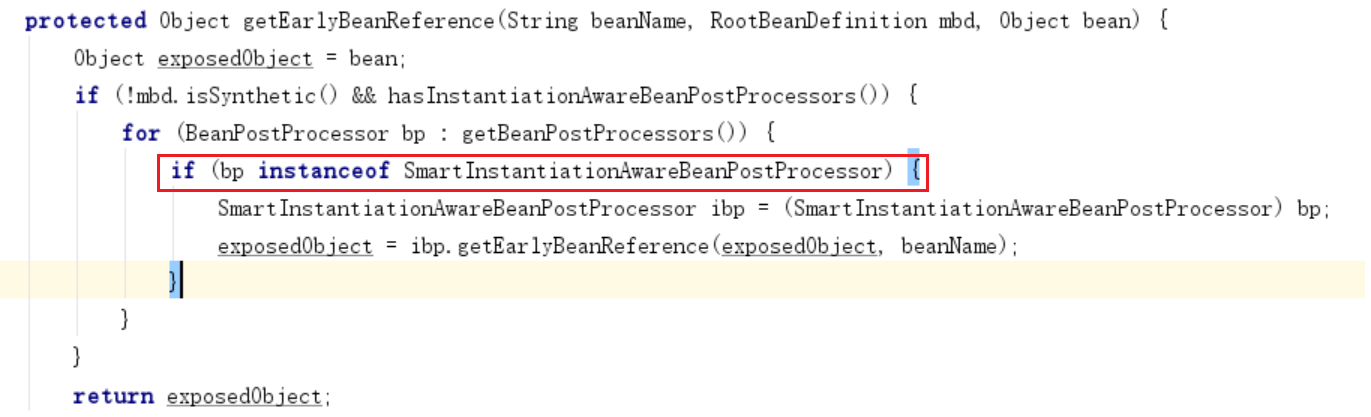
三级缓存的bean工厂getObject()方法,实际执行的是 getEarlyBeanReference(),如果对象需要被代理(存在beanPostProcessors -> SmartInstantiationAwareBeanPostProcessor),则提前生成代理对象。
二级缓存
根据以上步骤可以看出bean初始化是一个相当复杂的过程,但是貌似三级缓存已经解决所有问题了,二级缓存用来做什么呢?为什么三级缓存不直接叫做二级缓存? 这个应该是在缓存使用时决定的:
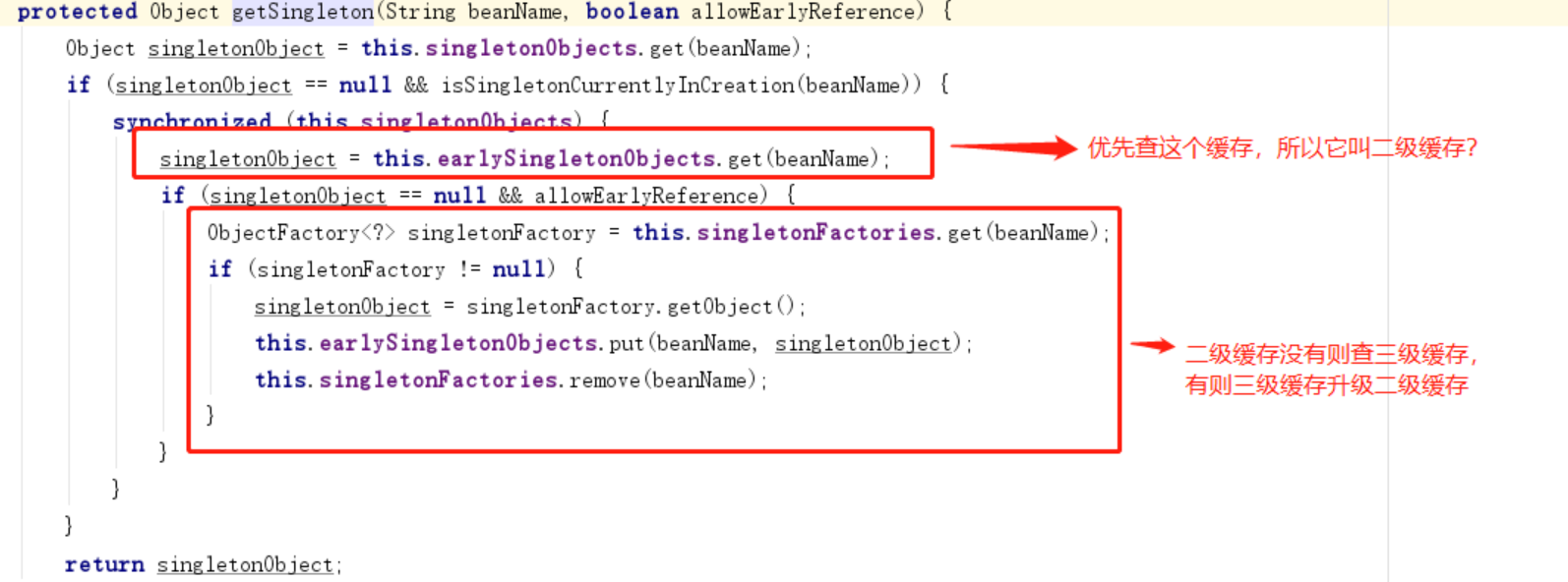
三级缓存
三级缓存中提到出现循环依赖才去解决,也就是说出现循环依赖时,才会执行工厂的 getObject() 生成(获取)早期依赖,这个时候就需要给它挪个窝了,因为真正暴露的不是工厂,而是对象,所以需要使用一个新的缓存保存暴露的早期对象(earlySingletonObjects),同时移除提前暴露的工厂,也不需要在多重循环依赖时每次去执行 getObject() (虽然个人觉得不会出问题,因为代理对象不会重复生成,详细可以了解下代理里面的逻辑,如 wrapIfNecessary() 方法)。
三、循环依赖的场景分析
不可用常场景
setter方式的、多例的循环依赖
只有单例的才会调用getBean()方法, 然后执行后续的循环依赖的代码块, 多例的不受spring生命周期管理所以不可用构造器循环依赖
在spring中解决循环依赖需要先实例化, 然后将对象引用暴露出到三级缓存, 如果是构造器循环依赖, 则会一直在实例化的时候无限递归实例化
可用场景
setter方式的、单例循环依赖特殊情况:A、B循环依赖,A先以setter方式注入B,B先后以构造器方式注入A
四、使用二级缓存能不能解决循环依赖?
使用二级缓存也可以分为两种:
使用
singletonObjects和earlySingletonObjects
或者
使用singletonObjects和singletonFactories但是不论使用哪两个缓存, 性质都是一样的, 因为
earlySingletonObjects保存的就是singletonFactories工厂返回的对象
理论上来说,使用二级缓存是可以解决 AOP 代理 bean 的循环依赖的。只是 Spring 没有选择这样去实现。
如果使用二级缓存解决循环依赖, 那么就意味着所有 Bean 都需要在实例化完成之后就立马为其创建代理,而 Spring 的设计原则是在 Bean 初始化完成之后才为其创建代理。