主键索引的设计
每个数据页中都有一个页目录,可以方便在当前数据页中进行数据的查询。但是如果有多个数据页的情况下,对于一个主键的查询,得知数据在哪个数据页显得尤为重要。
因此针对主键设计了一个主键目录,就是把每个数据页的页号以及数据页中最小的主键放在一起,组成一个索引的目录,如下图: 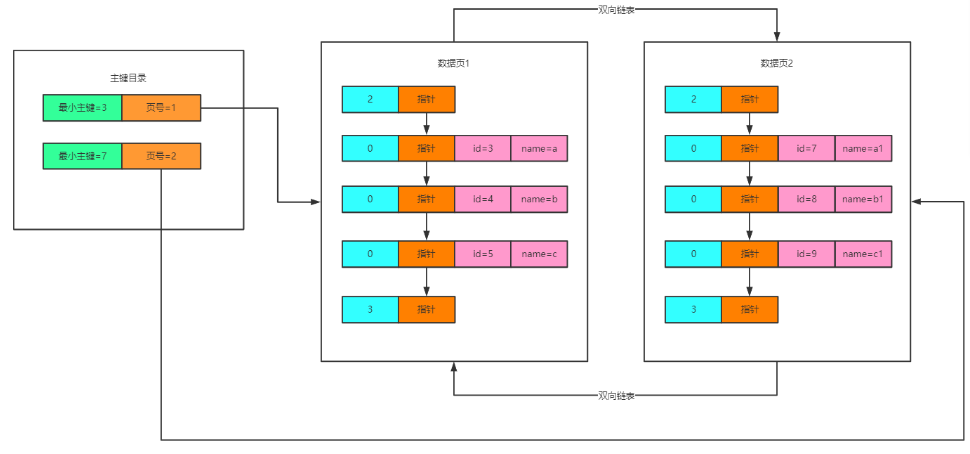
基于主键目录,先通过主键目录可以对比得到查询的数据可能在哪个数据页,然后到对应的数据页中基于二分法查找。
索引页
概念
当数据量超级大的时候,数据页的数量也非常的多。主键目录就得存放大量的数据页和最小主键值。性能没有得到突破。
此时,通过索引页来存放索引数据。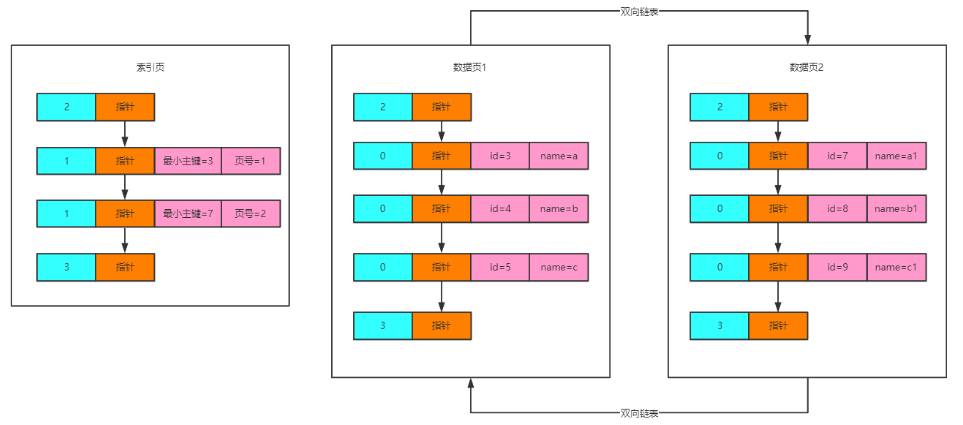
需要注意的是,索引页中,出现了类型为1的行数据。表示的是B+树非叶子节点。
虽然索引页多了,但是又应该到哪个索引页中去查主键数据,此时又可以把索引页进行一次“索引”,在更高层的索引层级中,保存了每个索引页里的最小主键值和索引页号。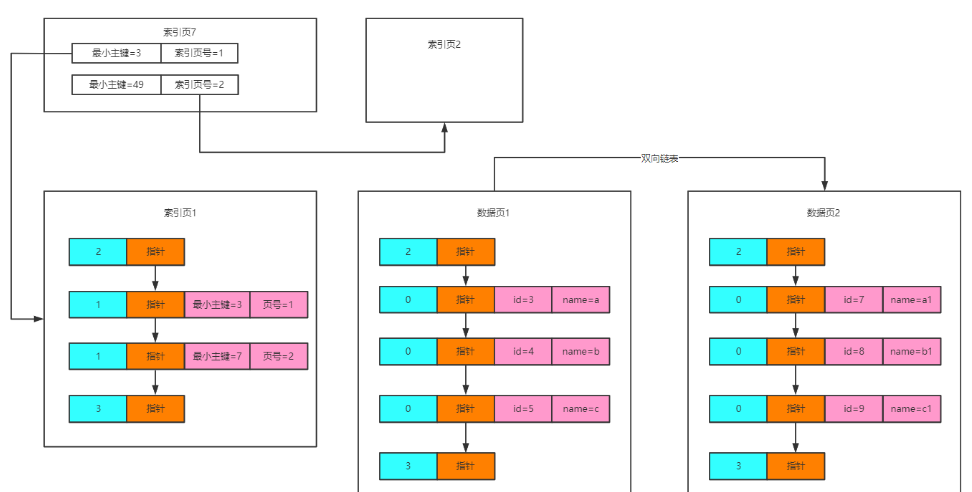
(如果跟高层的索引层级中数据也嫌多,那就继续套娃,这就形成了一个树结构)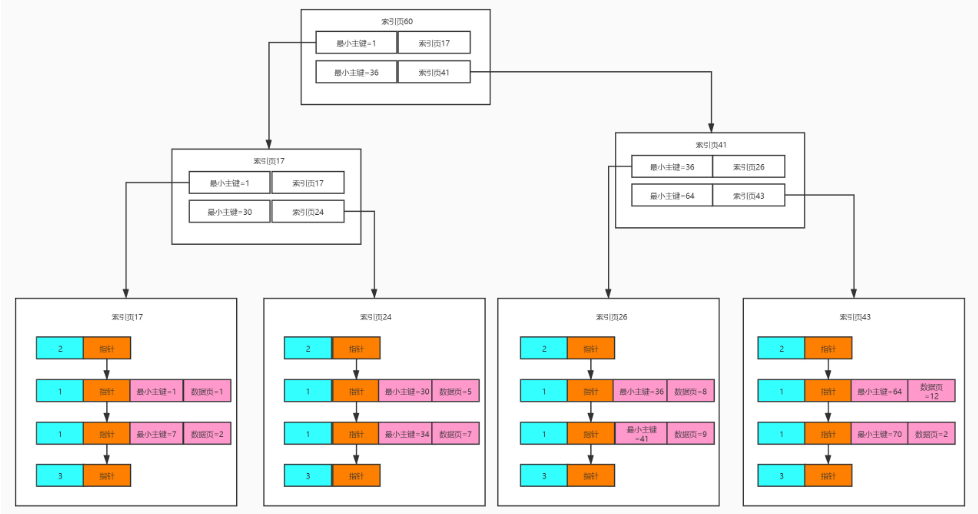
基于索引页的查找
如果要查询一个数据的主键为19,就应该先从顶层的索引页60里去找,通过二分法的方式得到下层要去索引页17中查找。然后一直找到了数据可能在数据页2中,然后去数据页2中,通过页目录,找到对应的槽位,读取数据。
索引分类
聚簇索引
如果在一个B+树索引数据结构中,叶子节点就是数据页本身,那么可以称这个B+数为聚簇索引。(innodb默认创建的一套基于主键的索引结构,表中的数据直接放在聚簇索引里,作为叶子节点的数据页)
二级索引
如果要对非主键的字段创建索引,那么会重新生成一颗B+树,叶子节点也是数据页,但是数据页中只会存放主键字段和对应的索引字段。
排序规则也是按照创建索引字段的顺序来严格排序的,也会有页分裂来保证顺序。
回表
在二级索引上进行查询时,比如对name字段建立的二级索引,当select name from xxx where id = xxx时,通过叶子节点中的数据页内容就能直接返回。
但是如果select from xxx where name = xxx时,叶子节点的数据不足以返回,还得通过主键去聚簇索引中定位到主键对应的完整数据行,此时才能把select 要查询的字段值全部拿出来。
联合索引
多个字段建立二级索引,也是一颗独立的B+树,叶子节点的数据页中包含了id,colA,colB。然后按照colA排序,如果colA相同就按照colB排序。
插入数据时如何维护不同索引的B+树
- 创建表时,就一个数据页。目前为空
- 开始插入数据,这个初始的数据页就是根页。数据页内部有一个基于主键的页目录,此时通过页目录查询就行。
- 数据越来越多数据页满了,创建一个新的数据页,然后把根页中的数据拷贝过去,同时再搞一个新的数据页,根据主键值的大小进行挪动,让两个数据页根据主键值排序,使得第二个数据页的主键值都大于第一个数据页的主键值。此时根页就变成了索引页。根页中存放了两个数据页的页号和他们里面的最小的主键值。
- 随着不停的增加数据,数据页不断的页分裂。索引页中的数据页索引条目越来越多,索引页开始分裂成两个索引页,然后根页继续往上走一个层级,引用两个索引页。
- 然后开始套娃。
与聚簇索引不同的是,二级索引的B+树的索引页中,除了存放页号和最小的索引字段值外,还会额外存放最小索引字段对应的主键值。
使用索引的几个原则
索引idx_abc(a,b,c)
等值匹配原则
where条件中字段采用等于连接,并且完全包含了索引中的所有字段。
比如where a=1 and b=2 and c=3
最左侧列匹配
采用索引中左侧的部分字段来查询,不能跳跃。
比如where a=1 and b=2 可以使用索引。但是where a=1 and c=3 不行。
最左前缀匹配原则
如果使用like查询,则最左侧不能出现通配符。
比如where a like '1%'。
范围查找规则
where语句里如果有范围查询,那只有对联合索引里最左侧的列进行范围查询才能用到索引!后续的字段无法使用到索引。
比如where a > 1 and a<5 and b<1只会使用a列的索引
等值匹配+范围匹配
按照前面的列等值匹配,后面的列范围匹配,需要注意的是,如果多列范围匹配只会生效最靠左的那一列。
比如where a=1 and b >1 and b<4 and c<5只会使用a,b列的索引
利用索引优化查询
SQL排序如何利用索引
对语句SELECT * FROM TABLE ORDER BY TOTAL_SCORE DESC, NAME DESC LIMIT 20,10
语句主要是把表根据总分降序,名字降序排序后从第20页取出10条数据,可以建立(TOTAL_SCORE,NAME)的一个索引,这样的话,直接从索引树中最大的数据开始进行偏移,然后读取10条数据就行。因为索引树本身自带排序。
这样的索引建立有一个前提,就是ORDER BY后面要么都是升序,要么都是降序,不能出现部分升序,部分降序。
SQL分组如何利用索引
通常而言,对于group by后的字段,最好也是按照联合索引里的最左侧的字段开始,按顺序排列开来,这样的话,其实就可以完美的运用上索引来直接提取一组一组的数据,然后针对每一组的数据执行聚合函数就可以了。
覆盖索引
如果我们建立了一个索引idx_name_age,那么我们在执行select * from student where name = '张三' and age >5 时,会先扫描一次idx_name_age索引,拿到主键后再去聚簇索引中查询一次,这叫做回表。但是如果查询的字段恰好是索引中的一部分,比如select name,这样的话,直接通过索引树就能够直接返回,这叫做覆盖索引。
如何尽可能的减少回表
在利用联合索引查询的实际情况下,往往可能因为回表到聚簇索引的次数太多,直接进行全表扫描。因此要尽可能的减少回表次数。
- 尽可能在SQL中指定要查询的字段名,尽量走覆盖索引
- 即便是要回表,尽可能使用limit,where等语句限定回表到聚簇索引的次数。
设计索引的考虑因素
- 实际查询中在where,group by,order by后面高频出现的字段
- 基数比较大的字段(基数:不同的数据对于同一个列的不同值,比如性别这一列的基数最大只能是2,而出生年月日因人而异就会很多)
- 字段类型比较小的字段
- 如果非得在varchar(255)这样的字段上建立索引,也可以考虑只建立前20个字符的一个索引。
- 对索引列使用函数会导致无法使用到索引
- 不要建立太多的索引,因为新增数据可能会导致多个索引树的页分裂,很费时间
一款交友软件,陌生人搜索相关的索引建立过程
字段的确定
- 省份provice
- 城市city
- 性别sex
- 年龄age
如果where和order by中的字段不同,建立谁的索引?
对于SQL:SELECT * FROM USER WHERE provice = '四川' order by age = 24
WHERE条件和ORDER BY使用了不同的字段;建立PROVINCE的索引,ORDER BY利用不到索引;建立age的索引,WHERE条件利用不到索引;如果建立联合索引Idx(province,age)也解决不了问题,只能二选一建立索引。
以where条件中的字段建立索引,因为基于where筛选可以最快速度筛选出所需要的少量数据。如果数据量不是特别大的情况下,order by的成本也不会太大
如何跳过基数很小的字段在索引中的位置
对于建立了索引idx(provice,city,sex,age)的SQL:
SELECT * FROM USER WHERE provice = xx and city = xx and age = 15
上面的SQL,说明了对于sex的条件没有勾选;
因为sex的基数最大是2。上面的SQL在已有的索引下,是无法通过age在索引中进行筛选的。但是可以通过添加上sex in ('male','female') 这个等值条件,使得索引生效。
根据七天内是否在线作为过滤条件
原始字段:latest_login_time
如果添加了这个字段,势必会利用latest_login_time的一个大于或者小于操作来筛选数据,但是在idx(provice,city,sex,age)的情况下,修改索引为(provice,city,sex,latest_login_time,age)也会导致age使用不到索引。
新增字段:does_login_in_latest_7_days(基数为2,原理同sex,利用等值查询)
通过对基数很小的字段进行索引的创建
对于SQL:SELECT * FROM USER WHERE SEX = 'female' ORDER BY VIP_SCORE DESC LIMIT 0,10
如果只是建立索引idx(sex),上面的SQL经过索引后依然有海量的数据,再进行磁盘文件排序,性能很低。
再这样的情况下,可以针对于基数很低的字段再加上一个排序字段单独设计一个辅助索引,idx(sex,score)。此时依然可以使用到索引来排序。因为sex='female'的数据在磁盘上是排在一起的。找到这一部分数据后,他们肯定都是按照score排序的,此时根据score字段值的顺序去读取limit语句指定的数据就行。