一、线程安全 - 可见性、有序性
这个案例比较简单,就是t1线程中用到了stop这个属性,接在在main线程中修改了 stop 这个属性的值来使得t1线程结束,但是t1线程并没有按照期望的结果执行。
public class VolatileDemo {
public static Boolean stop=false;
public static void main(String[] args) throws InterruptedException {
Thread t1=new Thread(()->{
int i=0;
while(!stop){
i++;
}
}
);
t1.start();
System.out.println("begin start thread");
Thread.sleep(1000);
stop=true;
}
}二、volatile解决可见性问题
有volatile变量修饰的共享变量进行写操作的时候会使用CPU提供的Lock前缀指令。在CPU级别的功能如下:
- 将当前处理器缓存行的数据写回到系统内存
- 这个写回内存的操作会告知在其他CPU你们拿到的变量是无效的下一次使用时候要重新共享内存拿。
而volatile实现可见性问题的本质就是使用lock指令实现了内存屏障
在上面的程序中,可以增加 volatile这个关键字来解决,代码如下:
public class VolatileDemo {
public volatile static Boolean stop=false;
public static void main(String[] args) throws InterruptedException {
Thread t1=new Thread(()->{
int i=0;
while(!stop){
i++;
}
}
);
t1.start();
System.out.println("begin start thread");
Thread.sleep(1000);
stop=true;
}
}三、为了提升处理性能所做的优化
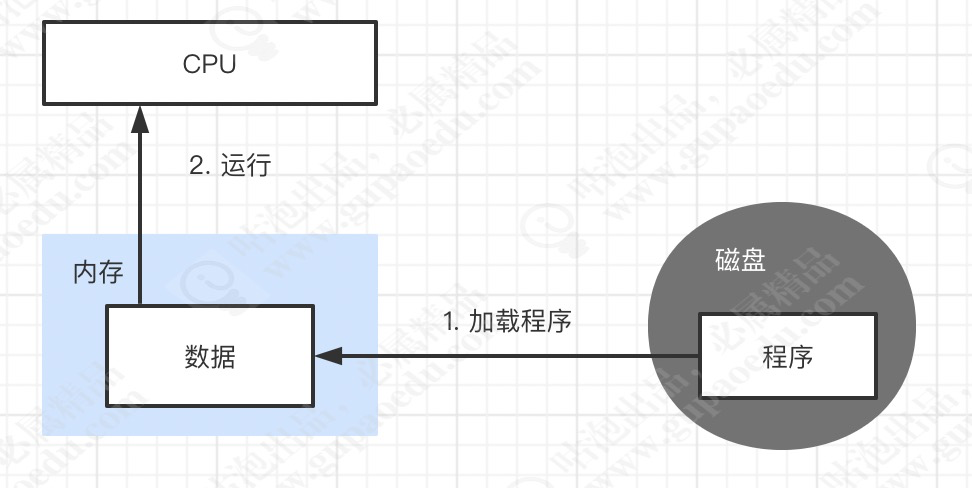
在整个计算机的发展历程中,除了CPU、内存以及I/O设备不断迭代升级来提升计算机处理性能之外, 还有一个非常核心的矛盾点,就是这三者在处理速度的差异。 CPU的计算速度是非常快的,其次是内 存、最后是IO设备(比如磁盘),也就是CPU的计算速度远远高于内存以及磁盘设备的I/O速度。
如下图所示,计算机是利用CPU进行数据运算的,但是CPU只能对内存中的数据进行运算,对于磁盘中 的数据,必须要先读取到内存,CPU才能进行运算,也就是CPU和内存之间无法避免的出现了IO操作。
而cpu的运算速度远远高于内存的IO速度,比如在一台2.4GHz的cpu上,每秒能处理2.4x109次,每次 处理的数据量,如果是64位操作系统,那么意味着每次能处理64位数据量。
虽然CPU从单核升级到多核甚至到超线程技术在最大化的提高CPU的处理性能,但是仅仅提升CPU性能 是不够的,如果内存和磁盘的处理性能没有跟上,就意味着整体的计算效率取决于最慢的设备,为了平 衡这三者之间的速度差异,最大化的利用CPU。
所以在硬件层面、操作系统层面、编译器层面做出了很 多的优化
- CPU增加了高速缓存
- 操作系统增加了进程、线程。通过CPU的时间片切换最大化的提升CPU的使用率
- 编译器的指令优化,更合理的去利用好CPU的高速缓存
每一种优化,都会带来相应的问题,而这些问题是导致线程安全性问题的根源,那接下来我们逐步去了 解这些优化的本质和带来的问题。
四、CPU层面的缓存
CPU在做计算时,和内存的IO操作是无法避免的,而这个IO过程相对于CPU的计算速度来说是非常耗时,基于这样一个问题,所以在CPU层面设计了高速缓存,这个缓存行可以缓存存储在内存中的数据,CPU每次会先从缓存行中读取需要运算的数据,如果缓存行中不存在该数据,才会从内存中加载,通过 这样一个机制可以减少CPU和内存的交互开销从而提升CPU的利用率。
对于主流的x86平台,cpu的缓存行(cache)分为L1、 L2、 L3总共3级。

五、缓存一致性问题
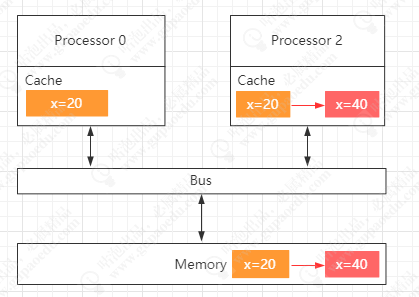
CPU高速缓存的出现,虽然提升了CPU的利用率,但是同时也带来了另外一个问题--缓存一致性问题,这个一致性问题体现在。
在多线程环境中,当多个线程并行执行加载同一块内存数据时,由于每个CPU都有自己独立的L1、 L2缓存,所以每个CPU的这部分缓存空间都会缓存到相同的数据,并且每个CPU执行相关指令时,彼此之间不可见,就会导致缓存的一致性问题,据图流程如下图所示:
六、缓存一致性协议
为了达到数据访问的一致,需要各个处理器在访问缓存时遵循一些协议,在读写时根据协议来操作,常见的协议有MSI,MESI,MOSI等。最常见的就是MESI协议。接下来给大家简单讲解一下MESI。
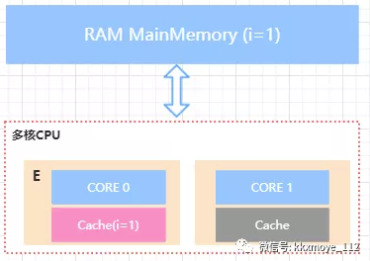
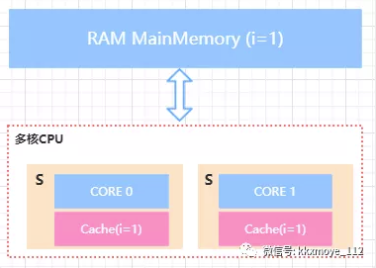
MESI表示缓存行的四种状态,分别是
- M(Modify[ ˈ mɒdɪfaɪ]) 表示共享数据只缓存在当前CPU缓存中,并且是被修改状态,也就是缓存的 数据和主内存中的数据不一致\
- E(Exclusive[ɪkˈskluːsɪv]) 表示缓存的独占状态,数据只缓存在当前CPU缓存中,并且没有被修改
- S(Shared[ʃerd]) 表示数据可能被多个CPU缓存,并且各个缓存中的数据和主内存数据一致
- I(Invalid[ ˈɪnvəlɪd]) 表示缓存已经失效
在CPU的缓存行中,每一个Cache一定会处于以下三种状态之一
- Shared
- Exclusive
- Invalid

七、指令重排序代码
public class SeqExample {
private volatile static int x=0,y=0;
private volatile static int a=0,b=0;
public static void main(String[] args) throws InterruptedException {
int i=0;
for (;;){
i++;
x=0;
y=0;
a=0;
b=0;
Thread t1=new Thread(()->{
a=1;
x=b;
//
x=b;
a=1;
}
);
Thread t2=new Thread(()->{
b=1;
y=a;
//
y=a;
b=1;
}
);
/**
* 可能的结果:
* 1和1
* 0和1
* 1和0
* ----
* 0和0
*/
t1.start();
t2.start();
t1.join();
t2.join();
String result="第"+i+"次("+x+","+y+")";
if(x==0&&y==0){
System.out.println(result);
break;
} else{
}
}
}
}八、伪共享代码
public class CacheLineExample implements Runnable{
public final static long ITERATIONS = 500L * 1000L * 100L;
private int arrayIndex = 0;
private static ValueNoPadding[] longs;
public CacheLineExample(final int arrayIndex) {
this.arrayIndex = arrayIndex;
}
public static void main(final String[] args) throws Exception {
for (int i = 1; i < 10; i++){
System.gc();
final long start = System.currentTimeMillis();
runTest(i);
System.out.println(i + " Threads, duration = " +
(System.currentTimeMillis() - start));
}
}
private static void runTest(int NUM_THREADS) throws InterruptedException {
Thread[] threads = new Thread[NUM_THREADS];
longs = new ValueNoPadding[NUM_THREADS];
for (int i = 0; i < longs.length; i++) {
longs[i] = new ValueNoPadding();
}
for (int i = 0; i < threads.length; i++) {
threads[i] = new Thread(new CacheLineExample(i));
}
for (Thread t : threads) {
t.start();
}
for (Thread t : threads) {
t.join();
}
}
@Override
public void run() {
long i = ITERATIONS + 1;
while (0 != --i) {
longs[arrayIndex].value = 0L;
}
}
public final static class ValuePadding {
protected long p1, p2, p3, p4, p5, p6, p7;
protected volatile long value = 0L;
protected long p9, p10, p11, p12, p13, p14;
protected long p15;
}
@Contended //实现对齐填充
public final static class ValueNoPadding {
// protected long p1, p2, p3, p4, p5, p6, p7;
//8字节
protected volatile long value = 0L;
// protected long p9, p10, p11, p12, p13, p14, p15;
}
}九、内存屏障
CPU在性能优化道路上导致的顺序一致性问题,在CPU层面无法被解决,原因是CPU只是一个运算工具,它只接收指令并且执行指令,并不清楚当前执行的整个逻辑中是否存在不能优化的问题,也就是说硬件层面也无法优化这种顺序一致性带来的可见性问题。
因此,在CPU层面提供了写屏障、读屏障、全屏障这样的指令,在x86架构中,这三种指令分别是SFENCE、LFENCE、MFENCE指令,
- sfence:也就是save fence,写屏障指令。在sfence指令前的写操作必须在sfence指令后的写操作前完成。
- lfence:也就是load fence,读屏障指令。在lfence指令前的读操作必须在lfence指令后的读操作
前完成。 - mfence:也就是modify/mix,混合屏障指令,在mfence前得读写操作必须在mfence指令后的读写操作前完成。
在Linux系统中,将这三种指令分别封装成了, smp_wmb-写屏障 、smp_rmb-读屏障、smp_mb-读写屏障 三个方法